In two years of blogging I have created over 320 posts. Obviously, some entries are very brief - maybe just a few words about a bug fix or report. In others, I was more in depth - for instance, when I wrote about the difficulty of estimating phylogenetic signal on very small trees; or when I discussed how to include fossil phenotypes in the estimation of ancestral states. If printed as a book (and, who knows, perhaps it will one day form the basis for one), the phytools blog would be a dense tome containing over 350 pages. Yikes!
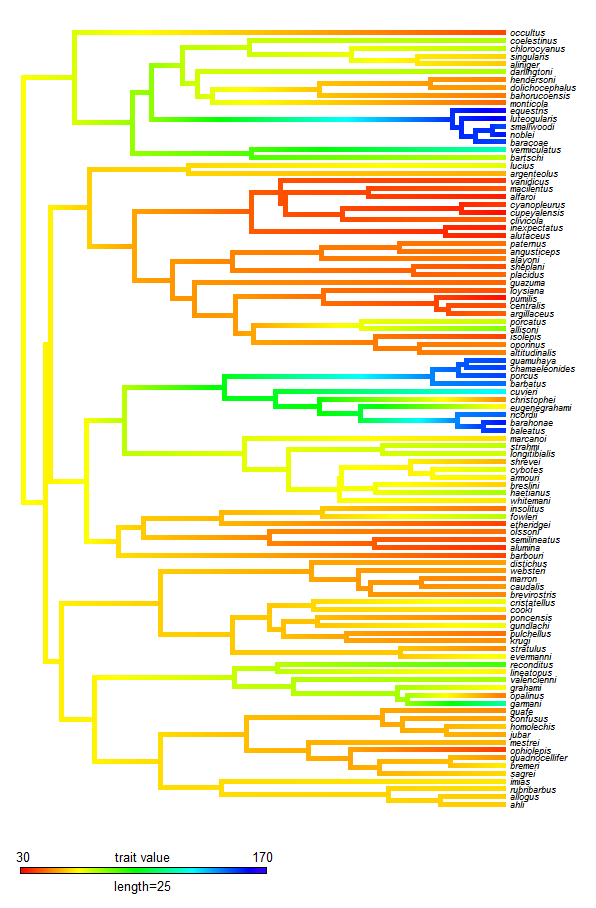
The phytools blog has also grown in popularity over the past year. Raw "pageview" counts can be affected by many things, and are thus difficult to interpret, but phytools blog has received over 90,000 pageviews since it's creation - over 60,000 in the past year. By any measure, that rate is growing - and this also equates to over 160 pageviews/day for 2012. Among the posts accruing the greatest number of pageviews in 2012: my series on xkcd style trees (e.g., 1, 2, 3); my entries on visualizing trait evolution on trees using colors (e.g., 1, 2); and my posts about ancestral character estimation under the threshold model from quantitative genetics (e.g., 1, 2, 3).
The phytools package (also on CRAN) has grown as well. From a small hodgepodge of methods, phytools has grown into a big one - now containing over 80 different functions and a PDF manual that (as of latest CRAN release) contained 87 pages.
Towards the end of 2012, phytools blog got a new look. Since when the original visual theme was created, phytools had no plotting functions (but now it has tons), this seemed appropriate. The blog also got a new URL (after I obtained the domain phytools.org).
I don't doubt for a second that 2013 will be just as productive as 2012 - so thanks for reading, and please keep coming back. Happy holidays!